アナライザーの設定
シミュレーションで実行した結果に対して何らかのポスト処理を行って統計解析をしたり、可視化したりするケースはよくあります。 OACISにはそのようなポスト処理の実行を行う仕組みも用意されており、Analyzerと呼んでいます。 ここではAnalyzerの設定方法や実行方法などについて解説します。
Analyzerの登録と実行
ジョブの実行後、実行結果に対してポストプロセス(Analyzer)を定義することができます。 OACISで定義できるAnalyzerには2種類存します 一つは各Runに対して実行されるもの、もう一つはParameterSet内のすべてのRunに対して行われるものです。 前者の例としては、シミュレーションのスナップショットデータから可視化を行う、時系列のシミュレーション結果に対してフーリエ変換する、などがあげられます。 後者の例は、複数のRunの統計平均と誤差を計算することなどがあげられます。
OACISの用語として、Analyzerによって得られた結果はAnalysisと呼ばれており、AnalyzerとAnalysisの関係は、SimulatorとRunの関係のようなものです。
Analyzerの実行フローはSimulatorととても似ています。 Analyzerを実行するためのスクリプトが生成され、workerプロセスからSSH経由でリモートホストにジョブ投入されます。 実行可能なホストの一覧はAnalyzer登録時に指定します。 実行時に一時ディレクトリが作成され、その中にできたファイルは結果のファイルとして全て取り込まれ、ブラウザ経由で確認できるようになります。 Simulatorの場合と同じように、実行日時や実行時間などの情報が保存されますし、プリプロセスやバージョンの記録も同様に可能です。 出力ファイルに_output.jsonというファイル名のJSONファイルがあれば、それをデータベースに取り込みプロットすることも可能です。
また、Analyzerは実行時に解析用のパラメータを指定して実行することもできます。 例えば、時系列データを解析するときに最初の何ステップを除外するか指定したい場合などに使えます。 Analyzerの登録時にパラメータの定義を登録することができます。
Simulatorと異なるのは、Analyzerには解析対象となるRunのデータに実行時にアクセスできます。 ジョブの実行時に作られる一時ディレクトリに、Runの結果のファイルが配置されます。 解析対象がRunかParameterSetかによって配置の仕方が異なるため以下で個別に説明します
Runに対する解析
ここではRunに対する解析の例を示します。
時系列データを出すシミュレーションのanalyzerとして、時系列をグラフにプロットすることを考えます。 シミュレータが以下の形式のファイルをsample.datというファイル名で出力することとします。1列目が時刻、2列目がプロットするデータです。
1 0.25
2 0.3
3 0.4
Analyzerの実行時には、Runの結果は実行ディレクトリ以下の _input/ というディレクトリに配置されます。 Analyzerはそのディレクトリにあるファイルを解析できるように実装する必要があります。
Runの結果のファイルすべてがAnalyzerには必要ではない場合、Files to Copyというフィールドに必要なファイル名を指定するとそのファイルだけが_inputディレクトリにコピーされます。
不要なファイル転送が減るのでAnalyzerの実行が速くなる場合があります。
ファイル名の指定にはワイルドカード(‘*‘)が利用でき、デフォルトの値は’*‘になっています。
複数のファイルを指定する場合は、複数行に分けて入力してください。
上記の例にあるような入力の時系列をgnuplotでプロットしましょう。 次に示すようなgnuplot入力ファイルを作成し、どこかのパス(例として ~/path/to/plotfile.pltというパスにする)に保存します。
set term postscript eps
set output "sample.eps"
plot "_input/time_series.dat" w l
これでAnalyzerの準備ができたので、OACISに登録します。 Simulatorの画面を開き、[About]タブをクリックするとAnalyzerを新規登録するためのリンク[New Analyzer]が表示されます。 そのリンクをクリックすると下図のような登録画面が現れます。
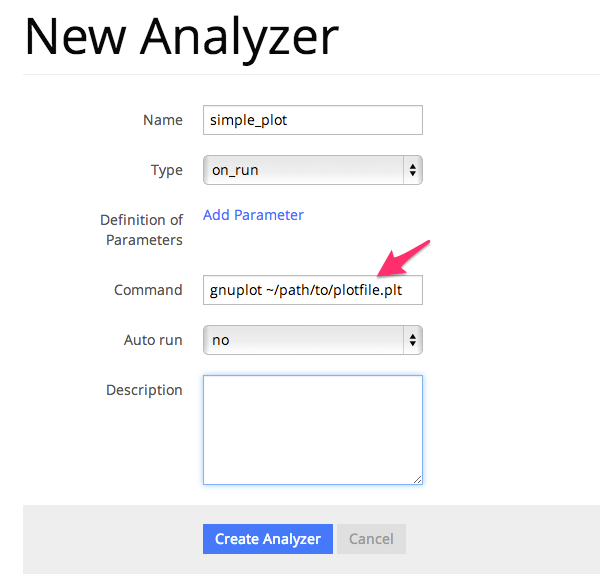
このページの入力フィールドにAnalyzerの情報を登録します。入力する項目は以下の通り。
| フィールド | 説明 |
|---|---|
| Name | OACISの中で使われるAnalyzerの名前。任意の名前を指定できる。各Simulator内で一意でなくてはならない。 |
| Type | Runに対する解析(on_run)、ParameterSetに対する解析(on_parameter_set)のどちらかから選ぶ |
| Definition of Parameters | 解析時に指定するパラメータがあれば登録する。空でも可。 |
| Pre process script | プリプロセスとして実行するスクリプトを入力します。空白可。 |
| Command | Analyzerを実行するコマンド。 |
| Print version command | Analyzerのバージョンを標準出力に出力するコマンド。 |
| Input type | JSON入力か引数入力か指定する。 |
| Files to Copy | 解析時に_inputディレクトリにコピーするファイルを指定する。 |
| Support MPI | MPI並列の場合はチェックを入れる。Analysis作成時に並列数を指定できるようになる。 |
| Support MPI | OpenMP並列の場合はチェックを入れる。Analysis作成時に並列数を指定できるようになる。 |
| Auto Run | Runの終了後に解析が自動実行されるか指定する。(後述) |
| Description | Analyzerに対する説明。入力は任意。 |
| Executable on | 実行可能なホスト。Analyzerを実行できるホストにチェックを入れる |
| Host for Auto Run | 自動実行で作成されるAnalysisが実行されるHost (後述) |
ここでは、Nameを”plot_timeseries”、Typeをon_run、他はデフォルトのまま、コマンドには以下を入力します。
gnuplot ~/path/to/plotfile.plt
このようにAnalyzerを登録するとRunの実行後に”plot_timeseries”というAnalyzerを選択してAnalysisを作成できるようになります。 Analysisが作成されるとRunと同様にバックグラウンドで処理され、完了後の解析結果はブラウザ上で閲覧できるようになります。
今回のサンプルでは示されていないが、パラメータを受け付けるAnalyzerの場合には _input.json というファイル内に解析のパラメータが記入されます。
Runに対する解析の場合、 _input.json のフォーマットは以下の通りです。
“analysis_parameters”, “simulation_parameters” はそれぞれ解析パラメータ、シミュレーションパラメータを表します。
{
"analysis_parameters": {
"x": 0.1,
"y": 2
},
"simulation_parameters": {
"L": 32,
"T": 0.5,
"_seed": 1787809130
}
}
ParameterSetに対する解析
ParameterSetに対する解析もRunに対する解析とほぼ同様です。
ただし、_input/ディレクトリに保存される形式と _input.json の形式が異なります。
_input/ディレクトリ内のファイルの構成は以下の通り
_input/
#{run_id1}/ # run_id1 の結果のファイル
xxx.txt
yyy.txt
#{run_id2}/ # run_id2 の結果のファイル
xxx.txt
yyy.txt
..... # 以後、ParameterSet内で"finished"になっている全てのRunの結果が同様に配置される
_input.jsonファイルの形式は以下の通り
{
"analysis_parameters": {
"x": 0.1,
"y": 2
},
"simulation_parameters": {
"L": 32,
"T": 0.5
},
"run_ids": [ // runのIDの一覧
"run_id1",
"run_id2",
"run_id3"
]
}
Runに対するAnalyzerの場合と同じように、Files to Copyというフィールドに必要なファイル名を指定するとそのファイルだけが_inputディレクトリにコピーされます。
例えば、”xxx.txt”というファイル名を指定した場合のディレクトリ構成は以下のようになります。
_input/
#{run_id1}/ # run_id1 の結果のファイル。xxx.txt以外のファイルは含まれない。
xxx.txt
#{run_id2}/
xxx.txt
..... # 以後、ParameterSet内で"finished"になっている全てのRunの結果が同様に配置される
AnalyzerからRunの結果ファイルを取得する例(言語:ruby)
require 'json'
require 'pathname'
persed = JSON.load(open('_input.json'))
RESULT_FILE_NAME = 'time_series.dat'
result_files = persed["run_ids"].map do |id|
Pathname.new("_input").join(id).join(RESULT_FILE_NAME)
end
# => ["_input/526638c781e31e98cf000001/time_series.dat", "_input/526638c781e31e98cf000002/time_series.dat"]
Analyzerの自動実行
AnalyzerはRunの完了後に自動で実行することもできます。 各RunおよびParameterSetに対して毎回手動でAnalysisを作成する必要がなくなるので便利です。 自動実行するにはAnalyzerのAuto Runのフラグを設定します。
Runに対するAnalyzerの場合、Auto Runのフラグは yes, no, first_run_onlyから選択できます。
- yes: 各Runが正常終了した場合に自動で解析が実行される。
- no : 自動で実行されない。
- first_run_only: 各ParameterSet内で最初に正常終了したRunに対してのみ自動実行される。
- データの可視化など、一つのRunに対してのみ実行したい解析処理に対して使用できる。
ParaemterSetに対する解析の場合、Auto Runのフラグはyes, noの2択から選択可能です。 yesの場合、ParameterSet内のすべてのRunが :finished または :failed になったときに自動実行ます。